How do I build robust architectures?
In this article, we will explore building a robust architecture for a regional-scale customer that does online shopping. This article assumes some pre-existing knowledge on the Cloud and general Cloud concepts. Reach out to me if you would like other articles! In future, we will dive deeper into how one can build robust Cloud Applications that are high-available, fault-tolerant, reliable and secure.
Customer Summary
Go Mart, a brick and mortar supermarket operating in the Asia-Pacific region, has expanded into the online shopping space and this had resulted in high demand for their services. Due to their monolithic applications and an untrained IT team, they have been struggling to meet customer demands, leading to complaints about website performance and slow response times.
Solution Overview
My team and I proposed a cloud solution that offers Go Mart high availability, scalability, and robust security features. This solution incorporates a networking cloud implementation inclusive of a DNS Resolver, API Gateway, CloudFront Caching, and VPCs.
Through conducting load testing, security testing, and cost analysis, we provide an overview of how the solution is scalable and highly available, while also being cost effective and secure enough to meet Go Mart’s use cases. On hindset, there are some limitations of this solution, and we handed over the requirements on future areas for improvements to provide Go Mart with a North Star on next steps.
Technical Bits of the Solution
In this section, we’ll dive deep into the technology behind the solution.
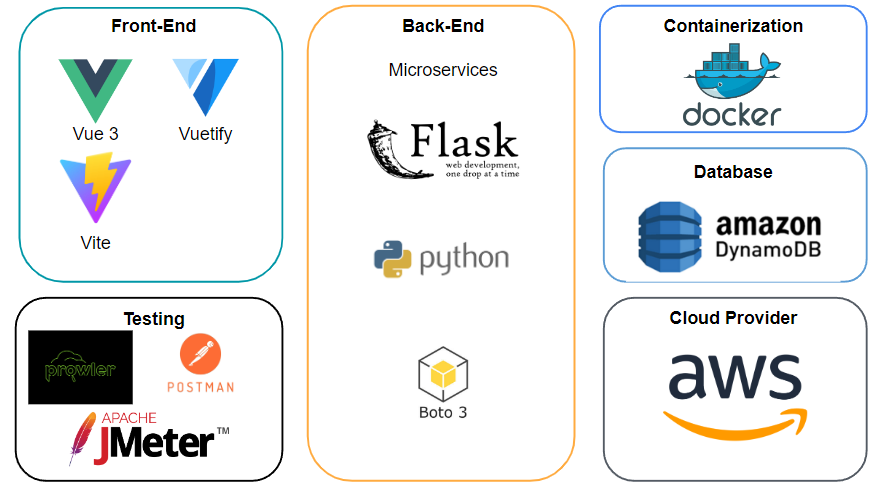
Technology Stack
We used many different technologies for the different use cases. The decisions behind these technologies were mainly towards the ease of use + familiarity that the team had with these technologies.
Solution Architecture
Our main compute cluster uses a microservices architecture deployed on ECS Fargate, and have utilised AWS Lambdas and ElastiCache for caching, whilst also creating proper IAM roles and policies to ensure selective privilege management.
To enable end-to-end delivery of our use cases, notification and data archival systems have been set up using AWS resources, and for external user data management, we have opted for AWS Cognito due to its flexible deployment options and encryption capabilities. Additionally, we have automated the deployment of both the frontend and backend applications using a CICD pipeline, and we have also incorporated AWS CloudTrail and CloudWatch for monitoring purposes.
This cloud solution also boasts a machine learning and analytics feature for our recommendation system, which serves to provide strong analytics support to the business teams and help Go Mart to hit its OKRs. This cloud solution also provides incident management capabilities using AWS SMIM, and adds on with analysing internal RPO and RTO using AWS Resilience Hub.
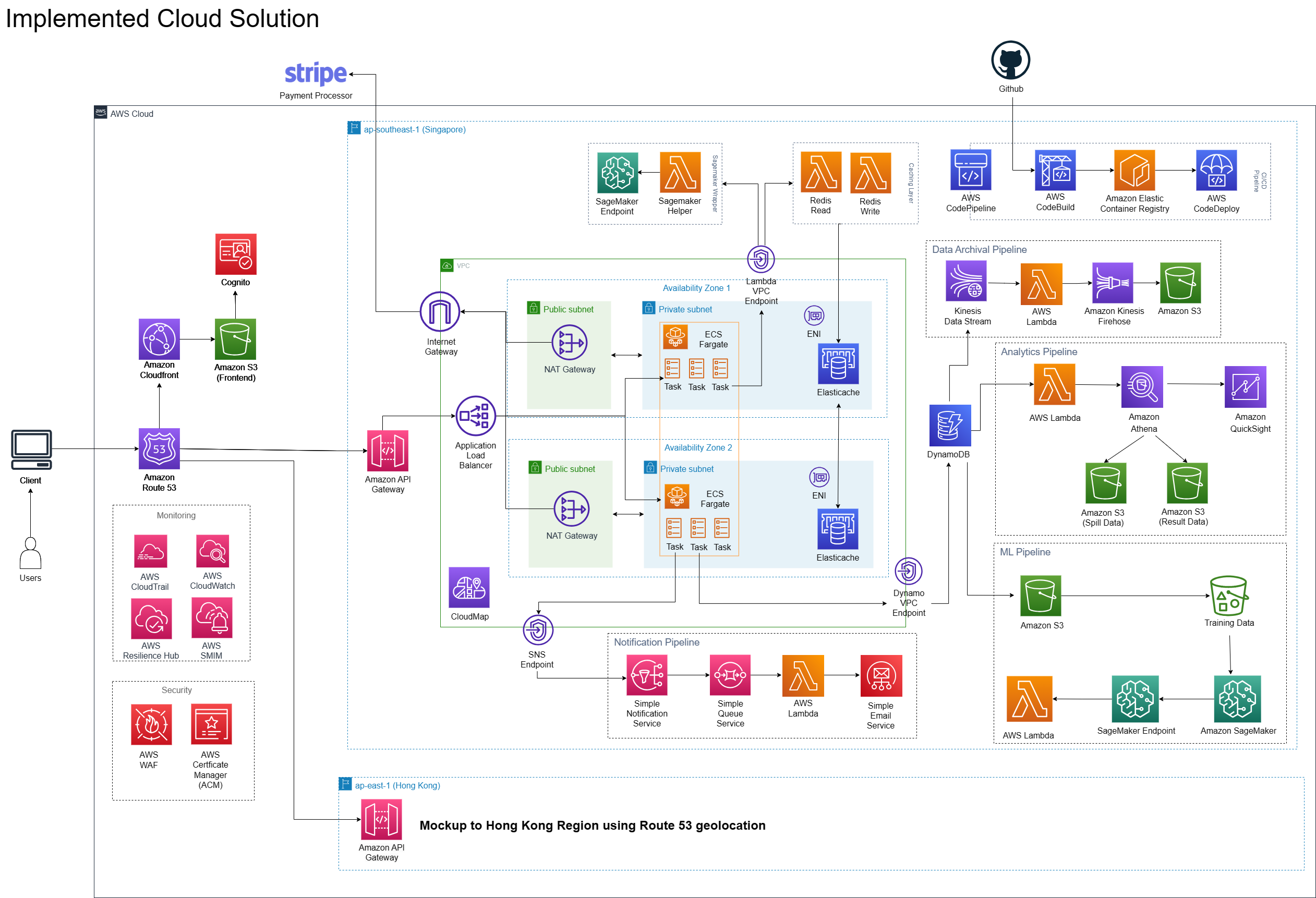
We’ll now breakdown the different components and talk about them.
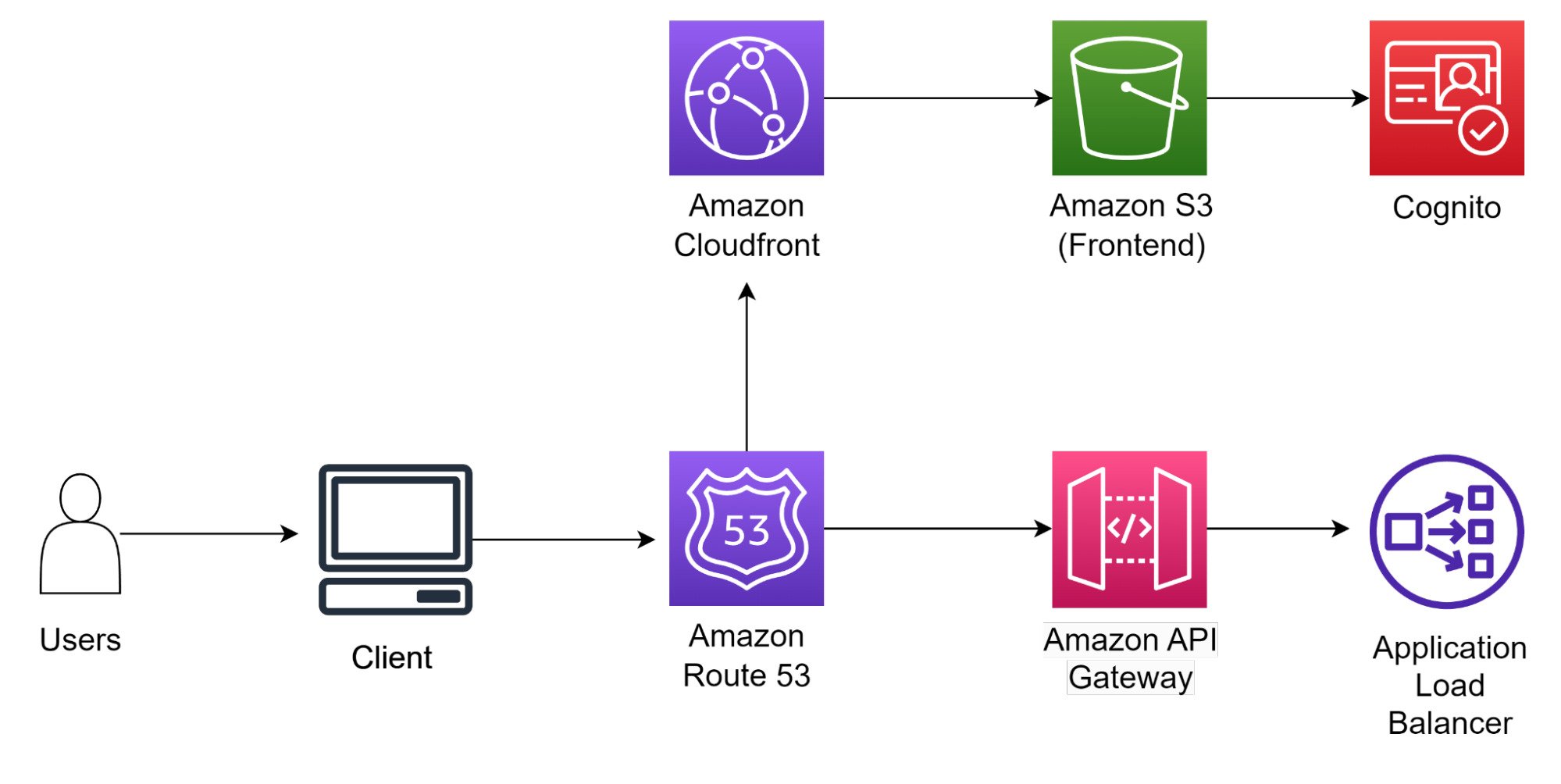
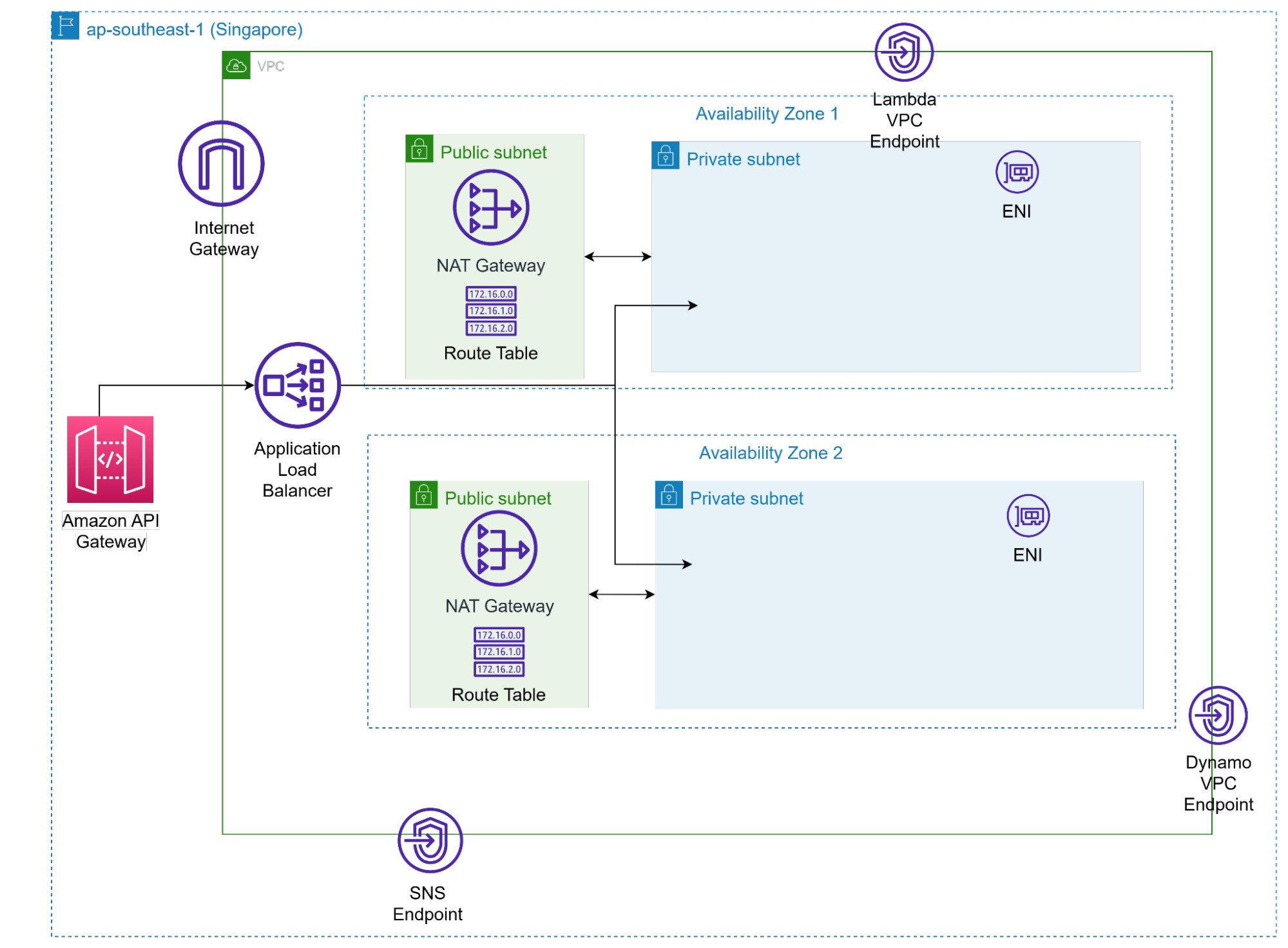
Networking
The entry point to the Solution lies in networking. Users will access Route 53, which is a DNS that will re-route users to the correct servers. Amazon CloudFront helps to cache the static files (images/HTML/CSS) that will be stored in Amazon S3. For API requests, they will go directly to Amazon API gateway and be fed into the ALB. The ALB helps to scale the backend application by distribution the load acress mutliple backend servers.
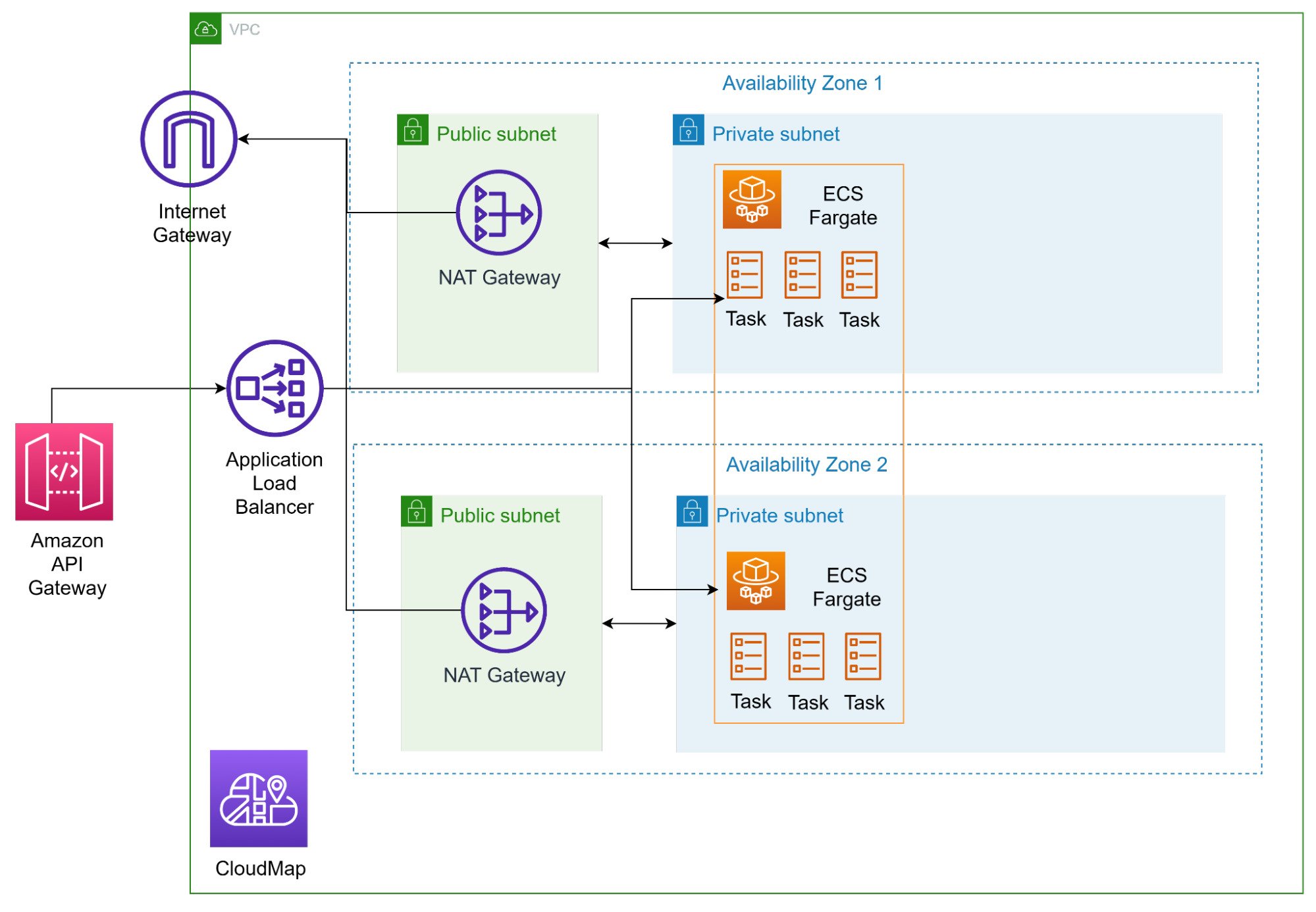
Fargate
The request gets routed past the API Gateway and into the VPC that hosts the compute cluster. In this case, we recommended fargate for a Serverless Solution that suits a microservices architecture. Fargate has tasks, and think of tasks as microservices. The differen tasks will handle different workloads, and each microservice will be deployed as 1 task.
We have implemented a multi-AZ solution for high availability, such that when 1 AZ goes does, the application will still be running.
The NAT Gateway essentially allows the fargate tasks to communicate with the internet, but blocks the internet from trying to directly access the fargate tasks.
Lastly, only the NAT Gateways are in public subnets, and everything else is in a private subnet that is not accessible to the public.
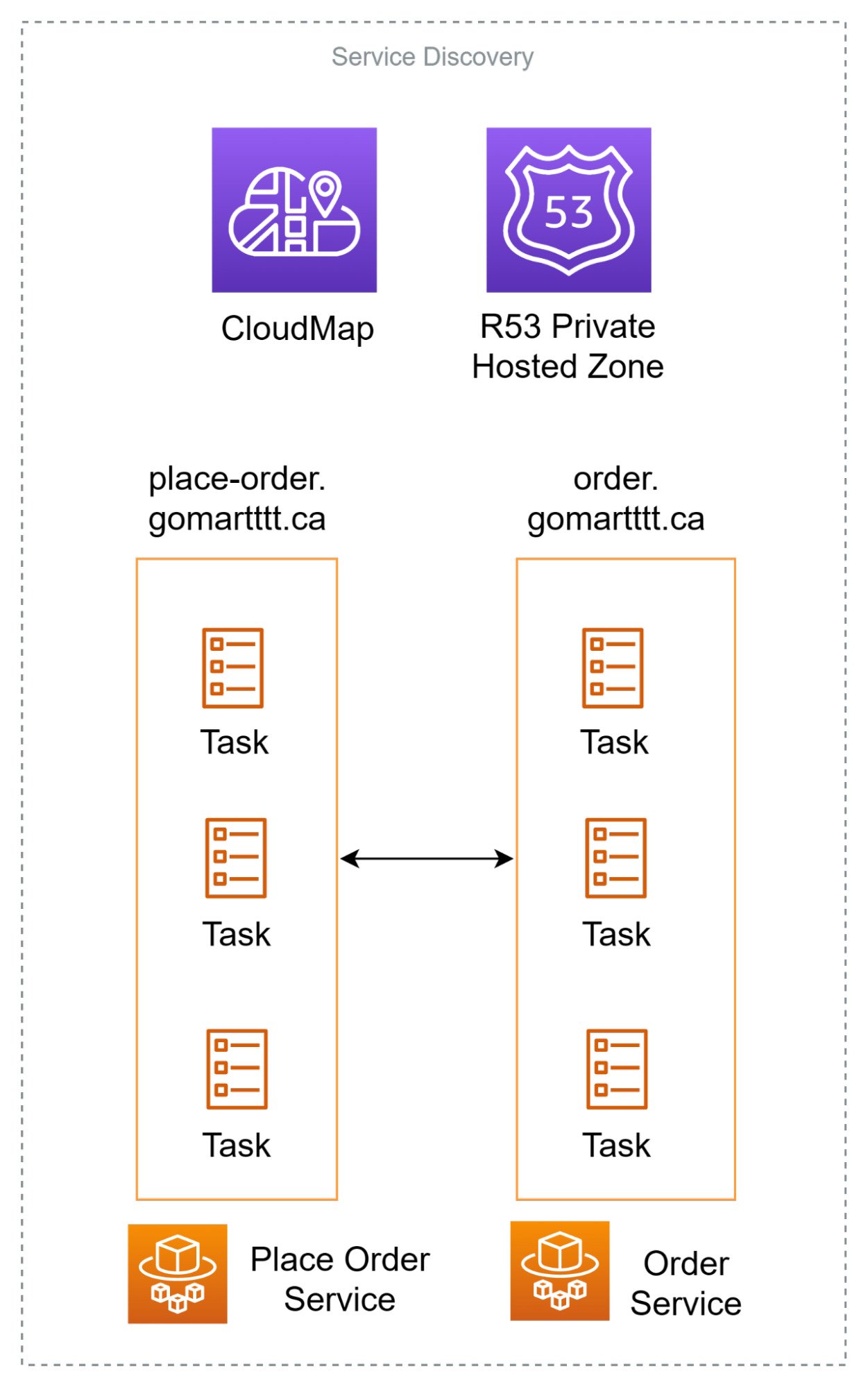
Service Discovery
One issue with microservices architecture is that it is very difficult for you to keep track of your services. In this case, the fargate tasks are ephemeral and will constantly change. Their IP addresses will change and we need a solution to dynamically query the hostname/IP of the fargate tasks.
We can use Amazon CloudMap for this, and it helps you to do service discovery. CloudMap is essentially R53, but in a private hosted zone. As new tasks get spun up/ de-registered, they will automatically create/delete A-records in the R53 hosted zone that point to themselves. This helps in service discovery as services now just need to make a call the CloudMap, to ‘discover’ the IP addresses of services.
VPC Endpoints, Route Tables, Elastic Network Interface (ENI)
Before we dive into the pipelines, there is this concept of VPC Endpoints that we must talk about. The pipelines are all located in “private” subnets in the AWS Cloud, and there must be a way to connect with them.
VPC Endpoints are bridges that help you access those private resources directly, from you private subnets, without having to go through the internet.
We have also configured route tables to allow traffic to flow to the correct subnets, or NAT Gateways if needed.
Lastly, would be the use of ENI. ENIs are crucial as it attaches an IP address into the subnet and is usually tagged to a service. This allows other services to call this IP address.
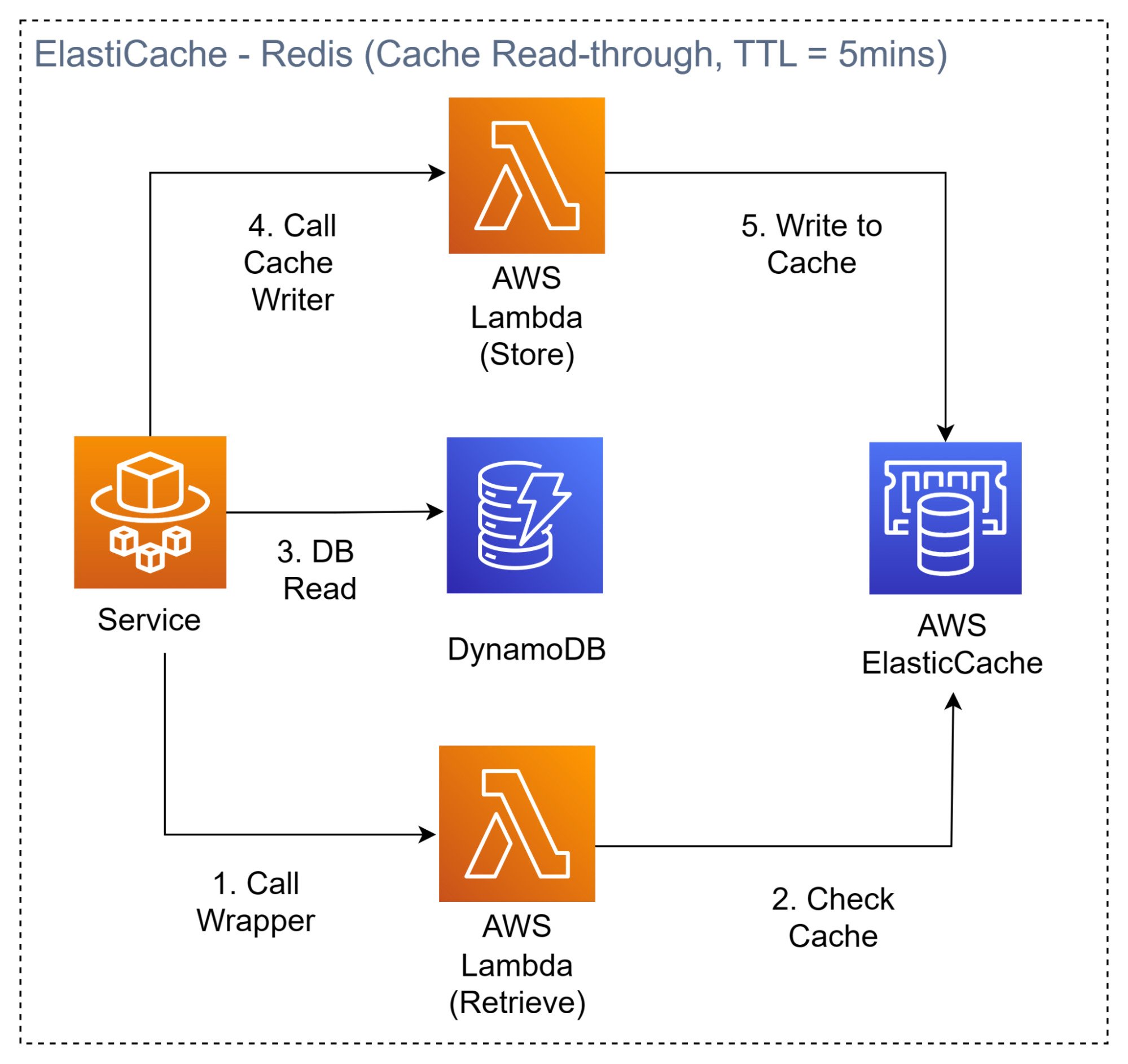
Database and Caching
We chose DynamoDB as a NoSQL Database. We had the option to use DynamoDB Accelerator (DAX) as a cache, but chose to use elasticache because DAX would be too expensive.
We also used a cache read-through strategy. We created some reader and writer lambda functions that will read/write to the cache/DB. A cache is necessary as it helps to relieve load from the Database and also helps to ensure milli/microsecond performance on your client side. The caching strategy works like that:
- Check if data in cache
- If data in cache: return
- If not in cache, read from DB, write to cache, return.
Analytics Pipeline
Go Mart needs Business Intelligence, and we designed a fully serverless Analytics Pipeline for their use case. Adequare data wil be fed from DynamoDB (DDB) into a lambda function. This function then transforms and places the necessary dat into Amazon Athena.
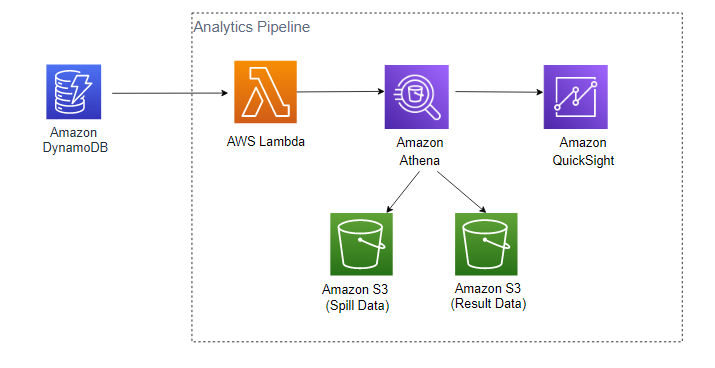
Amazon Athena and Amazon QuickSight come into play together, where Athena allows you to make SQL queries directly on your S3 bucket. QuickSight will then tap into these queries and you can instantly view your data on a dashboard.
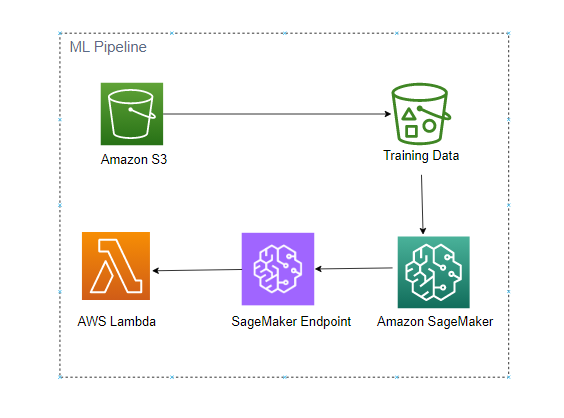
Machine Learning Pipeline
With the hype in Machine Learning, everyone wants a piece of the cake, and so does Go Mart. We taught them how to implement robust Machine Learning solutions with ease via this Pipeline.
Essentially, data wil be stored on S3, and they can use Amazon SageMaker to train a recommender system to recommend products to their customers.
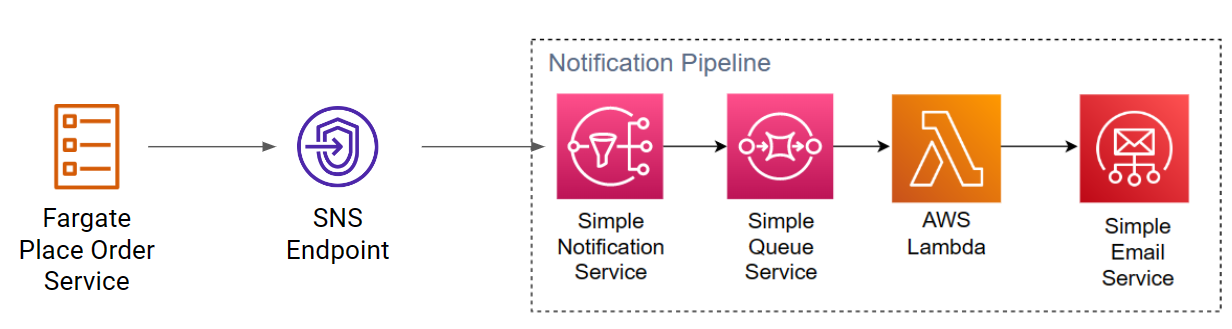
Notification Pipeline
Customers want to get notified when their order is scucessfully placed. You can design a notification pipeline that uses SNS and SQS to queue messages, and these messages can be fed into Amazon SES to be send out to customers when their order has been successfully placed.
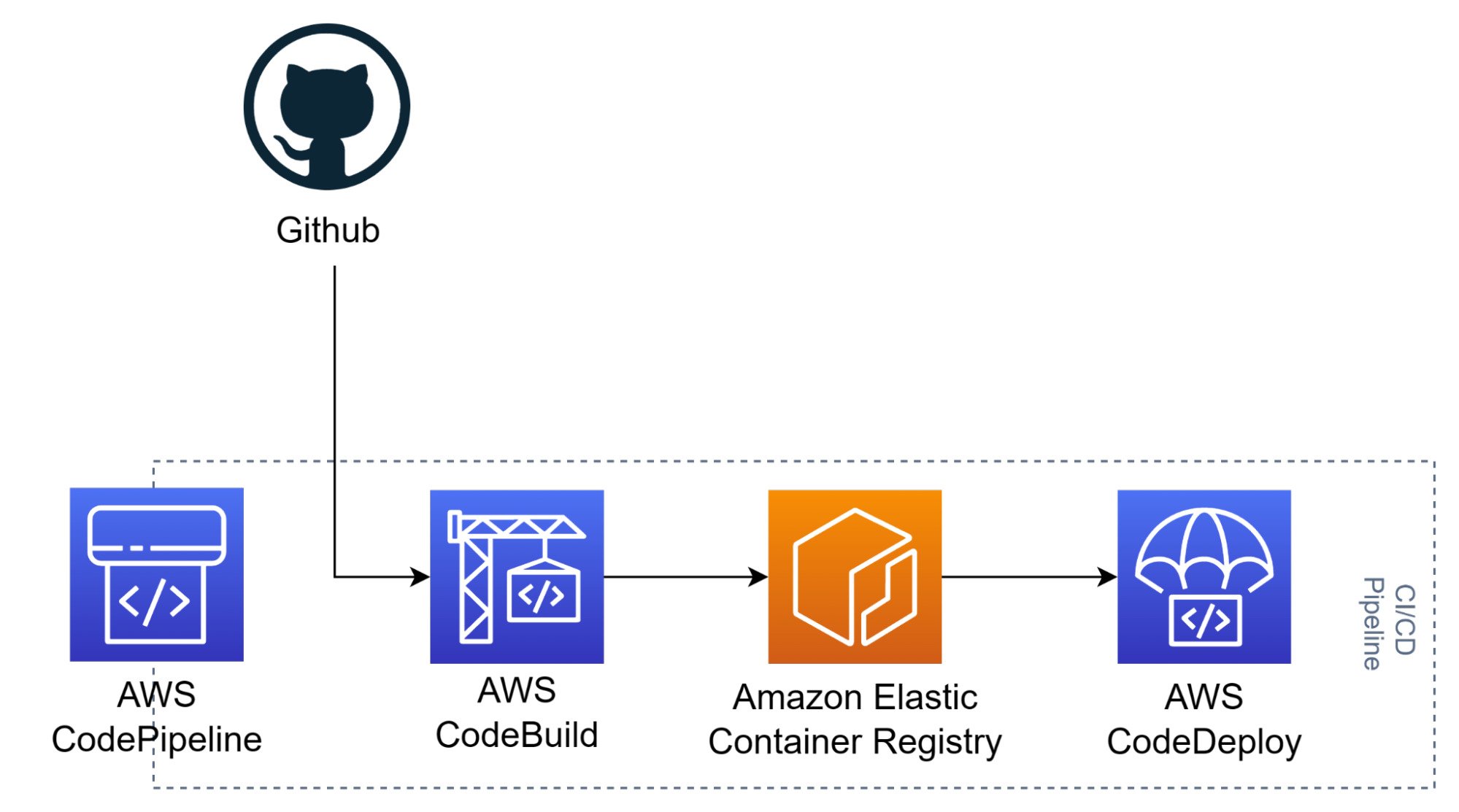
CI/CD Pipeline
It is now industry standard to have almost real-time code delivery and deployment. This helps when you’re working Agile, and you must constantly push your code into different environments to be tested. AWS has a suite of excellent services that we used in order to help accelerate the build and deployment time for Go Mart’s developers.
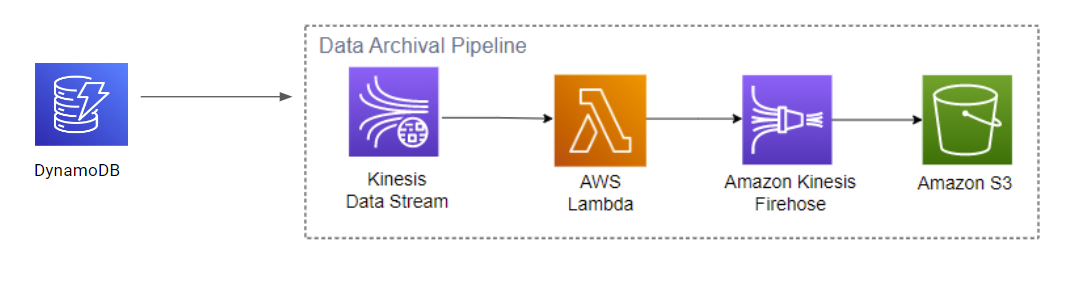
Data Archival Pipeline
Finally, we wrap up with the Data Archival Pipeline. Go Mart should archive their data to save costs, and also meet with regulatory and legal requirements. We want to archive their main data stored in DynamoDB, and we can use a streaming service to feed data into Amazon S3. The data stored in will be durable, cost less, and we will transition these data to “colder storage” such that they can cost even less than before, while still being durable and available (not instantly, but easily retrievable within a good timeframe).
Closing
We have explore how we can build purposeful pipelines on the Cloud. These pipelines can be assembled together to serve many different use cases and they are somewhat modular in nature.
There were still many other services used, such as monitoring services like CloudWatch and CloudTrail, or even security services like Certificate Manager, Web Application Firewall etc. But we’ll save that for another time. This post is getting too long!
Happy Building!